SynSense时识科技与中科院自动化所联合研究成果荣登国际权威期刊Nature子刊,引领类脑智能技术新纪元
人工智能,作为引领科技革命和产业变革的核心力量,正推动生成式AI技术如ChatGPT、Sora等不断取得新的突破,大模型的应用范围也日渐拓宽。然而,随着智能算力的飞速提升,能耗问题逐渐凸显,成为制约算力产品效能的关键瓶颈。传统计算机在信号与数据转换、高精度计算方面的能耗和时间成本不断攀升,深度学习模型的训练成本亦居高不下。
人脑能够运行非常复杂且庞大的神经网络,总功耗却仅为20W,远小于现有的AI。类脑智能作为一种受脑科学和神经科学启发的创新科技,采用神经形态计算,模拟人脑运作机制,旨在实现信息的高效处理,同时降低能耗、提升算力。与传统人工智能相比,类脑智能展现了一种全新的计算范式,为科技发展和产业变革提供了全新视角和可能性。
人工智能的革新:时识科技与中科院自动化所联合研究成果突破
近日,SynSense时识科技与北京中科院自动化所李国齐、徐波课题组合作,提出了一套以超低功耗边缘端应用为导向,能够实现动态计算算法,软硬协同设计的类脑智能SoC系统Speck™,整个系统在典型视觉场景中的实时功耗低至0.7mW。该成果以《Spike-based dynamic computing with asynchronous sensing-computing neuromorphic chip》为题,2024年5月25日成功刊登在国际顶级学术期刊《自然》(Nature)的子刊《自然-通讯》(Nature Communications)。

图1. 收录图(收录链接,点击阅读原文即可查看 https://www.nature.com/articles/s41467-024-47811-6)
研究充分证明了将人脑中复杂的高级神经机制融入到神经形态计算中所带来的无限可能。相关工作得到了国家杰出青年科学基金、国家自然科学基金委重点项目、区域创新联合重点项目的支持。这一重大研究成果不仅展现了类脑智能的巨大潜力和广阔前景,也为未来科技发展和产业变革注入了强大动力。
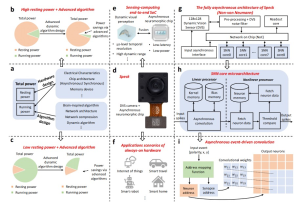
本篇文章首次详细的介绍了时识科技感算一体SoC芯片Speck™的设计细节(图2), 硬件资源和异步运算的核心技术。Speck™是一款异步感算一体的类脑智能SoC,采用全异步设计,在芯片上集成了动态视觉传感器(DVS)和类脑智能芯片,具有极低的静态功耗(0.42mW)。在视觉感知侧,DVS相机以异步方式运行,仅在视觉场景中亮度发生变化时,产生稀疏的事件流,能够以微秒级的时间分辨率感知视觉信息。在芯片侧,异步神经形态芯片同样以全异步方式设计,抛弃了全局时钟控制信号,避免了时钟空翻带来的能耗开销,仅在有事件输入时才会触发稀疏加法运算。
Speck™不仅实现了神经形态计算理论上具有低功耗和低时延优势,同时天然与神经形态动态计算契合。芯片的功耗主要分为静息功耗和动态功耗两部分。如图2b/c所示,传统AI芯片静态功耗高,在算法层面进行的能效优化对总功耗的降低作用不大。相比之下,Speck™具有极低的静息功耗,算法层面的能效优化能切实带来总功耗的降低。
Speck™包含多个SNN核心,每个核心都能够独立处理事件流,执行异步事件驱动的卷积操作。这种模块化的设计使得芯片能够灵活地处理各种规模的事件驱动任务。由于芯片的异步事件驱动特性,Speck™能够在接收到单个事件后立即更新系统状态,从而实现极低的输出延迟,为边缘计算场景提供了一个高能效、低延迟和低功耗的类脑智能解决方案。
脉冲神经网络(SNNs)与传统的人工神经网络(ANNs)最大的不同在于信息交换的方式。SNNs中的神经元通过脉冲序列(即0代表无信号,1代表有脉冲信号)来进行通信,而ANNs中的神经元则使用连续的数值来交换信息。这使得SNNs在运算时拥有一个动态的计算图,这意味着在任何时刻,只有一小部分神经元处于活跃状态,而其他神经元则处于闲置状态。相比之下,传统的计算模式,比如在GPU上运行的ANNs,则是基于静态计算图的。即便ANNs的所有输入或激活值都是零,网络也必须执行所有操作。通过将高层次的注意力机制整合到SNNs中,动态SNNs能够在显著降低能耗的同时,提升任务性能。这项技术创新点主要适用于希望提升计算效率和节能的智能设备和应用。
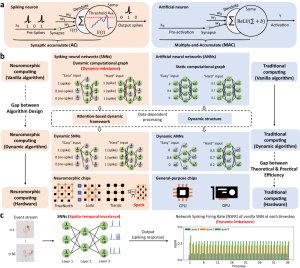 图3. 类脑计算和传统计算对比(从动态计算的角度)
文章中验证了动态平衡注意力机制和异步类脑芯片的结合可以在手势识别、明/暗光照下的步态识别等任务上取得准确率上、功耗和延时上巨大的提升。通过在类脑芯片Speck™上部署SNN,实验展示了一个实时功耗低至0.70mW的高精度类脑智能系统,整个系统处理单个脉冲的超低延迟仅为 3.36 µs。
图3. 类脑计算和传统计算对比(从动态计算的角度)
文章中验证了动态平衡注意力机制和异步类脑芯片的结合可以在手势识别、明/暗光照下的步态识别等任务上取得准确率上、功耗和延时上巨大的提升。通过在类脑芯片Speck™上部署SNN,实验展示了一个实时功耗低至0.70mW的高精度类脑智能系统,整个系统处理单个脉冲的超低延迟仅为 3.36 µs。
SynSense时识科技为Speck™芯片提供了完整的软件工具链,只需要使用编程框架Sinabs上完成SNN算法设计与训练,即可在Speck™上进行部署。如图4所示,在屏蔽不重要时间窗口内事件流后,输入为0时,Speck™不会触发任何计算。为验证神经形态动态计算的有效性,该研究在三个公开数据集进行了测试。在DVS128 Gesture上,融合了注意力动态计算的Speck™在任务精度提升9%的同时,平均功耗由9.5mW降低至3.8mW。
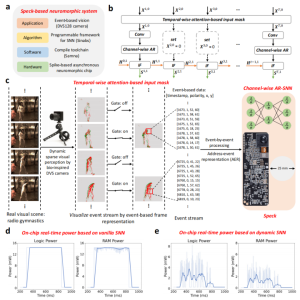
图4. 融合了注意力动态计算的Speck™
这项研究揭示了Speck™类脑计算感知平台和人脑的高级抽象功能间的工程映射关系,通过这种机制能够实现类脑智能在能耗、性能、延迟上的优越表现。充分证明了类脑智能在实际应用场景中,从高能效、低延迟和高性能等维度,其异步事件驱动、稀疏性和动态性等方面的巨大潜力。
AI技术的飞速发展让大型模型在复杂任务处理上展现出巨大潜力,但也对计算资源和数据传输速度的要求也日益增加。类脑智能技术为这一挑战提供了有效的解决方案,能够显著减少系统延迟及对中心化云服务的依赖,同时提升能源效率,降低运营成本。
科研成果高效转化是推动基础研究不断前进的源动力,如今类脑智能作为创新“密码”正在为发展新质生产力注入澎湃动能。面对当前算力瓶颈和能耗问题,为人工智能的发展提供了新的方法和视角。随着技术的持续进步,类脑智能将为AI的未来打开更广阔的应用空间,推动智能科技向更深层次、更广泛领域的发展。可以期待在不久的将来,类脑智能以科技撬动万亿规模的产业“新蓝海”。
中国科学院自动化研究所(Institute of Automation,Chinese Academy of Sciences)以智能科学与技术为主要定位,是中国科学院率先布局成立的“人工智能创新研究院”的总体牵头单位,是中国最早开展智能科学与技术基础理论、关键技术和创新性应用研究的科研机构,也是中国国内首个“人工智能学院”牵头承办单位。
作为人工智能领域的“国家队”,自动化所以国家战略需求为导向,聚焦人工智能领域重大基础科学问题及核心技术,确立了以“脑图谱与类脑智能”、“多模态人工智能系统”和“决策智能系统”为主攻方向的战略发展目标。自动化所现有包括多模态人工智能系统全国重点实验室、复杂系统认知与决策实验室、国家专用集成电路设计工程技术研究中心等国家平台,数个北京市及中国科学院科研平台,与国际及港澳台地区研究机构共建了中欧联合实验室、中国科学院香港创新研究院人工智能与机器人创新中心等国际合作创新平台。
研究所拥有一支人工智能领域建制化、体系化、高水平的科研队伍,包括中国科学院院士3人,发展中国家科学院院士1人,IEEE Fellow13人,国家杰出青年科学基金获得者15人,“万人计划”科技创新领军人才入选者12人,百千万人才工程入选者9人,科技部中青年科技领军人才6人,国家优秀青年基金获得者19人。