SynSense时识科技首创:“Chip-in-Loop”SNN代理训练,让芯片参与反馈,高效训练高精度SNN网络
SynSense时识科技于近日开辟了一种全新的SNN(脉冲神经网络)训练方法:与传统方案的显著区别是,SynSense时识科技提出的新方案让类脑芯片参与到整个SNN训练流程(loop)之中,而不仅仅是在服务器(训练设备)中执行复杂的数学运算,将有效保证类脑芯片在实际商业应用中的推理精度,提升用户实际体验。
这一全新的训练方法由SynSense时识科技高级算法应用工程师邢雁南、人工智能副总裁 Sadique Sheik及算法应用工程师凌于雅共同提出,目前已获发明专利授权,成为SynSense时识科技高价值、全方位类脑专利技术的重要部分。其无需过多辅助设施,利用已有设备和软硬件设施,所需成本和代价较低,是为脉冲神经网络提供的一种简洁但效果突出的商业训练方案。
芯片在环代理训练
同时消除转换误差、量化误差,提升精度
“由于ANN网络在调整网络配置参数时,所使用的损失是SNN网络的损失,因此最终的调整结果是最利于SNN网络(及其所在的SNN处理器)输出正确结果的方向,不仅消除了ANN转SNN时的转换损失,还消除了将SNN网络部署至SNN处理器时的量化损失,因而该方案十分有利于芯片的实际商业部署应用。”
在后人工智能时代,如何低功耗地实现边缘智能是学术、商业界普遍关注的重要课题,而仿生的脉冲神经网络SNN则是最有希望的研究方向之一。如何高效地训练(也称学习)出高精度脉冲神经网络则又是该领域极其重要且极具挑战性的研究内容。
当前脉冲神经网络主要训练方法
ANN转SNN:其基本理念是在使用ReLU函数的ANN网络中,连续的激活函数值可以由SNN中的频率编码下的平均脉冲发放率近似。该训练过程忽视了SNN自身所有的时域特性,存在转换误差,以及部署SNN至类脑芯片后,还存在量化误差。
反向传播:由于SNN中的脉冲神经元的激活是离散的、不可导的,这是直接应用反向传播最大的挑战,目前主要解决方案为代理梯度等。
延迟(latency)学习:定义神经元活动为其脉冲发放事件的函数,神经元最多触发一次,较强的输出对应较短的脉冲延迟。
串联(tandem)学习:由SNN和ANN通过权值共享分层耦合组成,在前向传递时,每一层ANN接收其输入作为前一层SNN的脉冲计数,因此,在后向传递时,每一层ANN根据输入脉冲计数计算其输出相对于共享权值的梯度。
然而,现有训练方案的训练结果部署到类脑芯片上后,普遍存在误差,导致芯片上的SNN网络表现与训练设备上的SNN网络表现存在差距。当前学术界一直在通过各种努力,降低这种差距。
鉴于此,SynSense时识科技算法团队提出了将ANN作为代理(proxy)且芯片在环(Chip in Loop)的SNN训练方法,是一种同时消除转换误差和量化误差的高精度芯片在环代理训练方法,开辟出一条全新的SNN训练道路。
这一新方案让训练设备中的ANN网络和类脑芯片中的SNN网络共享网络配置数据,将类脑芯片的推理误差反馈给ANN网络,并借助成熟的ANN学习方法调整共享网络配置数据,不仅消除了当前流行的ANN转SNN时的转换误差,同时还消除了将训练完毕的SNN部署至类脑芯片后的量化误差。主要包含以下步骤:
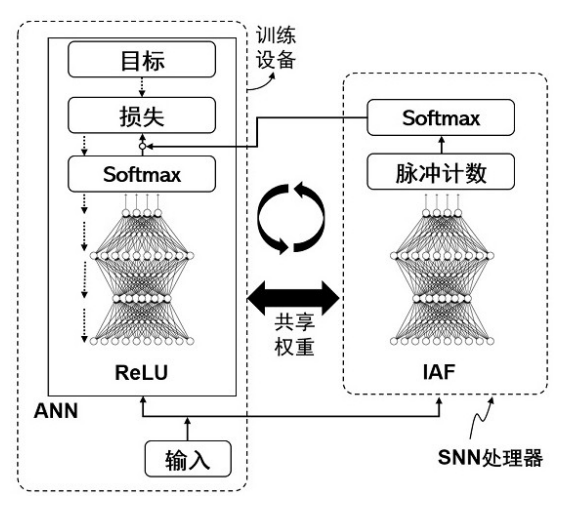
在训练设备中部署ANN网络,在包含SNN处理器的芯片中部署SNN网络,二者网络结构相同;基于输入的训练数据,SNN网络执行推理操作,获得SNN网络的输出脉冲序列;基于SNN网络的输出脉冲序列,获得当前网络损失。包括对SNN网络的输出脉冲序列计数,并执行Softmax处理获得Softmax值,再根据损失函数和输入的训练数据的目标值,计算所述当前网络损失。
在当前网络损失的基础上,借助反向传播,更新ANN网络和SNN网络共享的网络配置参数。
在两个网络接收下一批训练数据时,二者以相同的网络配置参数(比如权重数据)执行推理,且可以通过各种通信方式,将训练设备上更新后的网络配置数据传递/部署至芯片上的SNN处理器上,如此在执行下一轮训练时,ANN网络和SNN网络可以以相同的网络配置参数执行推理。
当执行完训练集中的数据或网络达到预设训练目标后,网络配置参数经过多次更新,获得最终的网络配置参数,即目标网络配置参数。
该方案与当前风靡全球的chatGPT所采用的人类反馈强化学习(RLHF)网络训练方案,在某些方面拥有着惊人的相似之处:只不过RLHF让人类参与训练,最终结果是让人类满意;而该方案让类脑芯片参与训练,最终让类脑芯片的表现满意。
面向一系列对功耗有着限制的商业应用环境,脉冲神经网络+SNN推理的处理器提供了一种适用于商用低功耗信号处理的绝佳方案。在已有方案的基础上,SynSense时识科技团队发挥创新实力,持续提出脉冲神经网络信号处理应用设计、训练的全新方向及优化方案,是SynSense时识科技类脑处理器实际部署应用的坚实基础,也是成功实现一系列高性能类脑应用、开发多样化类脑方案的关键步骤。
