SynSense demos neuromorphic processor in customer’s toy robot-EETimes
SynSense Demos Neuromorphic Processor in Customer’s Toy Robot – EE Times
At the Shantou (Chenghai) International Toy Fair, Swiss startup SynSense showed off its Speck neuromorphic processor plus dynamic vision sensor (DVS) module in a toy robot that can recognize and respond to gestures. The robot, developed by Chinese intelligent toy manufacturer QunYu, can copy human gestures, including crossing its arms and clapping.
“The toy market in general is very interesting for us,” Dylan Muir, VP of global research operations at SynSense, told EE Times. “It’s obviously a very high-volume market, which is of course always appealing… and the accuracy requirements for the application are modest. If your toy robot misses a gesture one time in 20, that’s no problem. Compared with high-resolution CCTV or autonomous driving, it’s a much simpler and easier application, which is also appealing.”
 SynSense customer QunYu has put the Speck module in a robot, using it as a low-power gesture sensor. (Source: SynSense)
SynSense customer QunYu has put the Speck module in a robot, using it as a low-power gesture sensor. (Source: SynSense)
Being in a toy doesn’t mean the company can’t also work on more stringent industrial robotics applications, but toys are “low hanging fruit,” Muir said.
“It’s a very easy, early market for us to get into and show that we are able to ship volume, we’re able to ship working products, [which is] obviously important for a company at our stage,” he said.
Dynamic vision sensors, which are based on the human retina, produce a low-bandwidth version of the scene, responding to changes in the scene only (called “events”). This low-bandwidth data is quicker to process than full-frame images. The DVS camera in SynSense’s Speck module is made by IniVation, but SynSense has also partnered with Prophesee for a higher-resolution module that will target different markets.
 SynSense and IniVation Speck module combines a DVS camera with a spiking neural network accelerator. This module is in the QunYu toy robot. (Source: SynSense)
SynSense and IniVation Speck module combines a DVS camera with a spiking neural network accelerator. This module is in the QunYu toy robot. (Source: SynSense)
There’s a clear synergy between DVS cameras and neuromorphic processors like SynSense’s, Muir said.
“We can natively use that very sparse image stream without doing [a full frame] conversion,” he said. “So we can really extract the full efficiency from that vision stream.”
This synergy is the reason Muir thinks the best chance of a successful commercial deployment for DVS cameras is together with neuromorphic processing.
“In my opinion, one of the main reasons [for the slow commercial adoption so far] is there isn’t a very easy way to process this data using commodity hardware [without converting to full frames],” he said.
Neuromorphic processors like SynSense’s spiking neural network accelerators are also seeing slow adoption so far.
“When I’m speaking to customers, I don’t use the word neuromorphic, I don’t talk about spiking neural networks, I don’t talk about DVS sensors or event-based imaging, because the customers don’t care about that,” Muir said. “They care about what you can deliver to them: Does it work? What’s the cost? What’s the energy consumption? What’s the performance? [Those are] the metrics they care about.”
Instead, SynSense’s approach to the market has been based on selling a camera plus processor module as a “smart sensor” or “gesture sensor,” he added.
The Speck module combines a 128 x 128-pixel IniVation DVS camera with SynSense’s spiking neural network processor, Dynap-CNN. The processor uses an asynchronous digital architecture tailored for vision applications (convolution); its simple model of the neuron is only “integrate and fire,” meaning the neuron state doesn’t decay when there is no output, reducing computational requirements.
The Speck module running continuous inference for gesture recognition uses a mean total active power of 8.74 mW during gesture interaction.
Leaky integrate and fire
SynSense has also been working on a second type of spiking accelerator for time-series data like audio, biosignals, vibration or accelerometer data. This chip, Xylo, has a different architecture compared to the earlier Dynap-CNN cores and has been through several tapeouts. The first Xylo dev kit is focused on audio, with the chip performing keyword spotting within a few hundred microwatts and latency below 200 ms.
“The [Xylo] family will have a common processor architecture, plus a number of very efficient sensory interfaces,” Muir said. “We have audio out already, we have an IMU sensor interface which we’re bringing up and testing at the moment… and then there will be other sensor interfaces for other classes of application as well.”
Xylo’s architecture is synchronous digital, unlike Dynap-CNN. The model of the neuron is more complex, simulating “leaky integrate and fire” neurons with configurable temporal dynamics. The core effectively runs a digital simulation of the spiking neuron dynamics; the length of time the neuron integrates over can be specified. While other solutions buffer snippets of audio and turn them into images for processing, Xylo operates on streamed audio data, meaning latency can be lower.
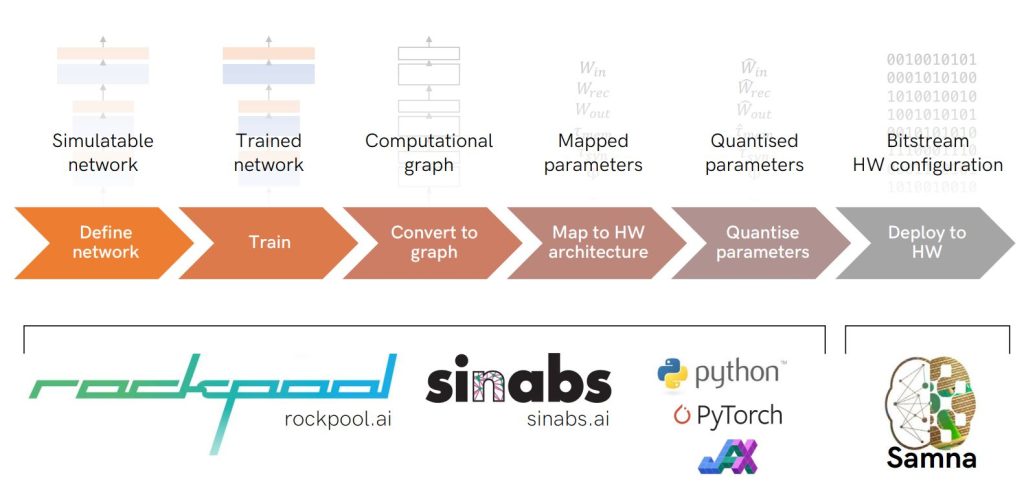
SynSense’s software stack. (Source: SynSense)
SynSense’s open-source software toolchain is designed to make the company’s chips easy to work with, even for those who have never worked with spiking networks before.
“We’ve made it much simpler than it has been historically to build these applications,” Muir said. “Now we have interns coming in that have never touched a spiking neural network and within a couple of months they’re deploying applications to our chips.”
Speck module and Xylo audio development kits are available now, with Xylo IMU development kits coming in around the end of 2023.
